UNEARTHED HEATSEEKERS
Predicting which songs from Triple J's Unearthed DAB+ radio station will be played on Triple J.
---
Overview_
Triple J Unearthed is the Australian music discovery initiative of Triple J. It has kicked off the careers of thousands of musicians, and hosts well over 120,000 tracks on its website. Triple J Unearthed has a full time digital radio station playing music selected from the website. One of the most important transitions an Australian musician can make is to transition from being played on Triple J Unearthed’s digital station to the ‘main’ Triple J station. This model is designed to predict which songs are going to make that transition.
In 2020 I wrote some code to automatically collect playlist data each week and gather as much information as I could about the artists included in that playlist. The result is a database including information like the time of day the song is being played, the genre of the artist, the length of the song, the hometown of the artist, the Facebook and Twitter audience of the artist and many more.
Each week when this data was collected it was added to the existing dataset. Then a machine learning algorithm was trained with validated data from up to one month before (I also checked which songs did end up being played on Triple J during the previous step). This made the tool smarter week by week.
Once the model was trained, it selected songs from the Triple J Unearthed digital station's playlist that received their first play recently and predicted which will of those would be played on Triple J. It then sent those predictions to this site. I stopped the project in 2021, to focus on other things once I felt like I had gotten to where I was aiming for. Here are the most recent predictions the model made:
As well as predictions, the model also told us how accurate it was during its training. Here is the latest report of its accuracy:
While making this weekly loop of collection and prediction might have been incredibly ineresting to work through, it was the 'learnings' that came from the various models' behaviour in testing that were the most rewarding. I was able to examine the data points that the models learned to let influence them. This information could be applied to other tools, useful for record label A&R in the future.
Technology Used_
The code ran on a stock Raspberry Pi 2 Model B sitting on a shelf in my home. It has a 900MHz quad-core ARM Cortex-A7 CPU and 1GB RAM. This credit card-sized computer is able to handle the process of gathering data, cleaning it, training the model and making predictions. The process is initiated by Cron.
The project was written entirely with Python. Here are a selection of the libraries used:
• Sci-Kit Learn for building the machine learning model.
• PyCaret for initial machine learning model comparisons.
• BeautifulSoup / Selenium / Requests for web scraping.
• Pandas for data frame management.
• FTPLib for transferring files to this web server.
• NumPy / SciPy for crunching numbers.
The model I used in the final build of this project is a Histogram-based Gradient Boosting Classification Tree. This model is a 'faster' implementation of a Gradient Boosting Classifier. For further reading on this, check the references at the bottom of this page.
Analytics_
Below are some graphics generated while building and training initial models during the early stages of this project.

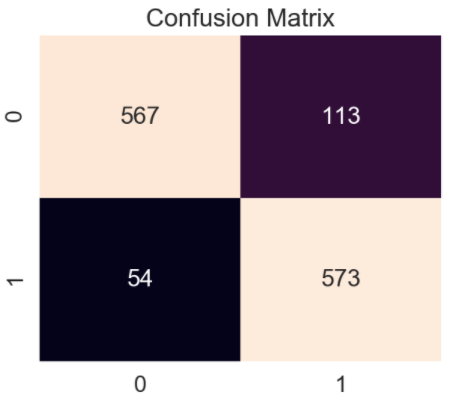
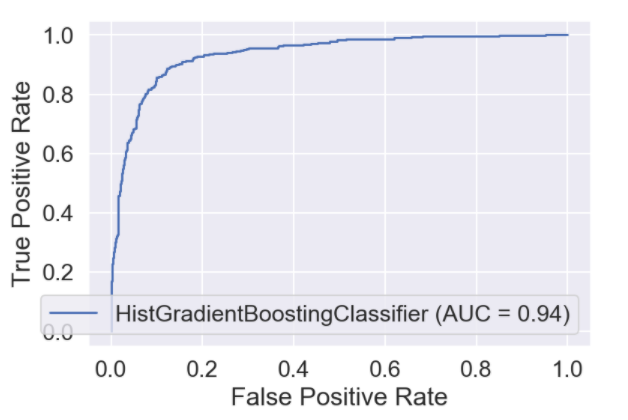

References_
I’ve collected a few resources for further reading:
• Triple J Unearthed on Wikipedia
• Cron on Wikipedia.
• MachineLearningMastery article on Gradient Boosting methods.
• Sci-Kit Learn documentation for HistGradientBoostingClassifier.
• Raspberry Pi 2 Model B product page.
• Article by Rahul Nayak about web scraping with Silenium and BeautifulSoup.
• PyCaret documentation regarding comparing classification models.
• TowardsDataScience article about understanding models with SHAP value.
© Copyright 2020 Tom Gilmore. All Rights Reserved.